Olá
A questão é a seguinte:
Estou comparando dois métodos de análises. O primeiro é o tradicional que é feito por um trabalhador experiente e treinado. Ele olha uma determinada amostra e avalia, distribuindo porcentagens em 6 categorias, como por exemplo:
Código:
A1 A2 A3 A4 A5 A6
20 20 45 15 0 0
Agora foi desenvolvido um equipamento que analisa estas 6 categorias de maneira automatizada:
Código:
A1 A2 A3 A4 A5 A6
3,3 15,3 65 16,4 0 0
Tenho cerca de 1300 amostras analisadas simultaneamente pelo trabalhador e pela máquina. Gostaria de um método que comparasse cada um dos tipos de análises e mostrassem similaridades e dissimilaridades entre as análises, e assim poder responder a questões como: "Em quais amostras houve maior divergência?" ou "Quais amostras máquina e humano classificaram de maneira mais parecida?"
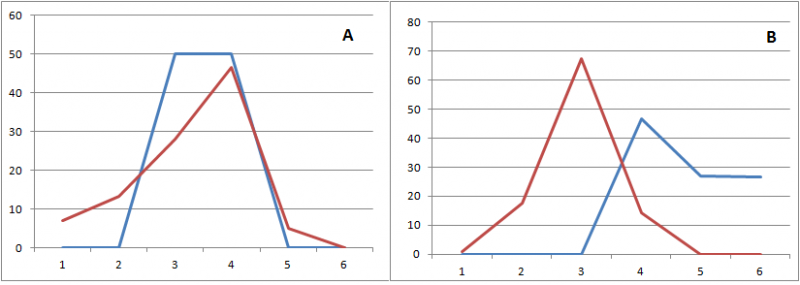
Temos, por exemplo, os gráficos A e B logo abaixo. Cada gráfico representa valores das análises da máquina (linha vermelha) e do trabalhador (azul). Notem que o gráfico
A apresenta uma similaridade maior que a representada pelo gráfico
B.
Anexo:
 graf.png [ 16.58 KiB | Visualizado 1314 vezes ]
graf.png [ 16.58 KiB | Visualizado 1314 vezes ]
É importante salientar que, nas análises de cada categoria (A1, A2, A3, A4, A5 e A6) a categoria A1 está mais próxima de A2 do que de A3. E A3 está mais próxima de A1 que de A6. Dessa forma, há uma similaridade maior quando o trabalhador atribui 100% em A2 e a máquina atribui 100% em A3 do que quando o trabalhador diz que 100% da amostra está em A2 e a maquina diz que a amostra está em A5. Este é o cerne da questão.
Já testei alguns métodos. Primeiro, realizei uma média ponderada com cada categoria, subtraindo a média de um em relação a média de outro. Quando a diferença fosse igual a 0 as análises seriam identicas e quando a diferença fosse igual a 5 elas seriam completamente diferentes. Mas na média reside um problema: se o trabalhador diz que uma Amostra tem 50% em A1 e 50% em A6, a média é igual a uma análise onde a máquina atribuiu os valores de 50% em A3 e 50% em A4.
Outros métodos que testei foram as Análises de agrupamentos (clusters), como a distância euclidiana e a Distância de Minkowsky. Entretanto esses métodos consideram cada variável (A1, A2 A3...) independentes uma das outras, e não consideram a questão de proximidade entre cada uma delas.
Alguém teria alguma luz?
Abraços
Hilton Ferraz
